
A pre-trained t-test transformer

Generally, neural networks are nonlinear function approximators. Unidimensional neural networks aren’t even particularly good at function approximation, but they are amazing in high-dimensional settings. Not only do they perform very well on high-dimensional vector inputs, but over the many years they have been around people have figured out how to use them effectively for matrix-valued inputs or even higher order blocks of numbers. We can define and learn how to evaluate functions with very complicated domains defined by arrays of numbers by various sizes. If you can phrase some input data as an array of numbers, chances are high that you can make progress on the problem using a neural network with enough data.
With the introduction of transformers, the machine learning community took another large step. Transformers have sets as domains. With transformers we can learn to evaluate functions that take a set as an input, and e.g., produces a number as an output. Many of the ‘functions’ we typically use are classically defined by multi-step algorithms. If you have enough data, you can learn to approximate these very complicated functions.
In many cases it’s possible to get arbitrarily large amounts of data through synthetic data generation.
As an example, we can think of performing a t-test. When you perform a t-test, you have two relatively small sets of numbers. From these two sets you calculate the t-statistic, then the degrees of freedom, and from that you can obtain a p-value. To simplify the problem, let’s consider the problem of calculating the t-statistic. Calculating the t-statistic isn’t a hard problem, but can serve as a useful example.
If we target the typical situation of having between two and ten observations per group, we can define a fairly simple transformer architecture that take these two sets as input.
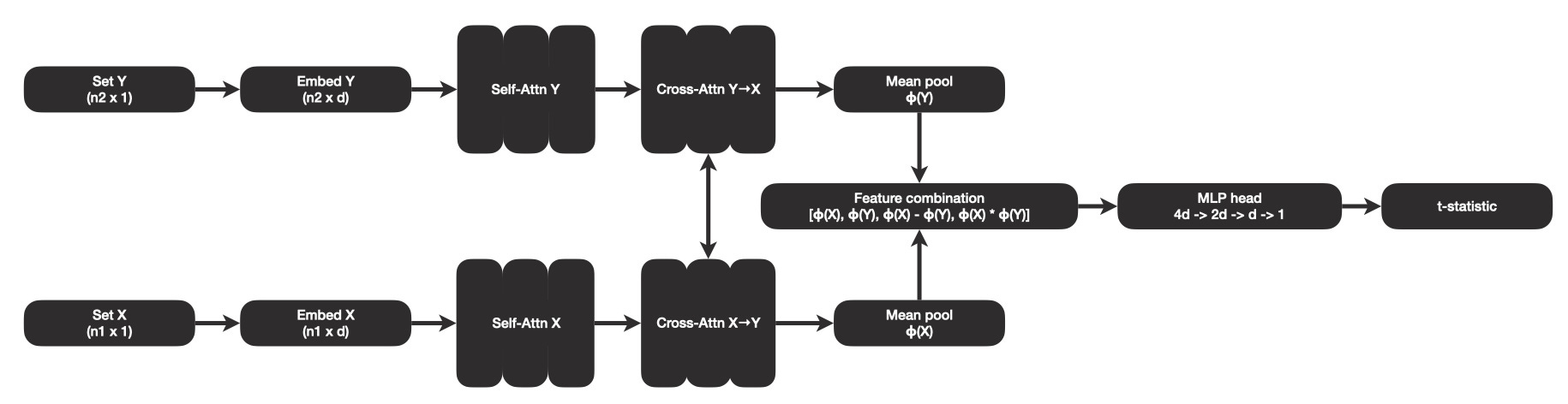
This transformer architecture has the ability to learn how to interpret within-group variation in the group, and how it relates to between-group variation. To train the model, we can sample random values for X and Y, of varying sizes, calculate our ground truth t-statistic, then give these as training data.
The model is relatively small, but still requires a large amount of training. I used ~20 million synthetically generated examples to train the model in total for the task of calculating t-statistics. Training took about six and a half hours on my Mac Mini. But after training, the pre-trained model can be reused to predict t-statistics.

The parameters for the pre-trained t-test transformer model takes about ~5 MB of storage (or ~2 iPhone photos).
I put together a package with the pre-trained t-test transformer in a Github repo: https://github.com/vals/TTT. I don’t suggest replacing standard t-statistics calculations, but the package illustrates the model architecture and training scripts. It is exciting thinking about other of functions defined with sets as domains we can learn.
