
An attempt at speeding up TSNE using Apple MLX

I’m often encountering situations where I want to do a quick 2D visualization of some data. A decent tool for this is TSNE (as well as the related tools UMAP and MDE).
A few years ago, fast CUDA-based GPU implementations of these tools became available from cuML and PyMDE, and I got used to being able to make a visualization in just a couple of seconds. Having switched to a Mac desktop for hobby projects, the most frustrating loss has been the ability to make these quick exploratory visualizations on the fly.
The extremely fast TSNE implementation in cuML from rapids.ai uses the FFT-accelerated approximation of tSNE originally published and implemented as FI-tSNE. Unfortunately, this implementation is challenging to install. To make optimized TSNE implementations available for use and experimentations, several variations of TSNE were implemented in the more user friendly package openTSNE, including the version using FFT approximation.
The M-series processors in modern Macs have unified CPU/GPU architectures, where GPU cores can be used for computationally intensive tasks. Apple has released the MLX library to enable general computations to take advantage of the GPU cores on the Apple silicon processors.
I was wondering if the FFT-accelerated TSNE could be implemented in MLX and speed up TSNE visualizations. I was also curious about using Claude Code for translating implementations to new frameworks, so this seemed like a good opportunity.
Using the openTSNE package as context, I had Claude Code create a native MLX implementation of TSNE (MLXNative), and, following that, an MLX implementation of the FFT approximation (MLXFFT).
The MLXNative implementation worked fine, while the MLXFFT implementation ended up with a some edge cases leading to outliers and some uncontrolled gradients. It also seems MLX is lacking some FFT functionality compared to the FFT implementations used in cuML and FI-tSNE/openTSNE.
My primary interest was the runtime speed when making use of the M4 Pro GPU. If runtimes were promising, I figured it would be worth digging in to minor, potentially fixable, issues.
I investigated how the runtime to create TSNE embeddings depended on dataset size for the implementations, and compared that to the various implementations in openTSNE, using either one or twelve cores. I also compared runtimes with the default scikit-learn implementation of TSNE.
In addition, I benchmarked the recently announced ‘zero code change’ cuML acceleration of the scikit-learn TSNE function. This used the same data, but was run on an L40S node on lightning.ai instead of locally on the Mac.
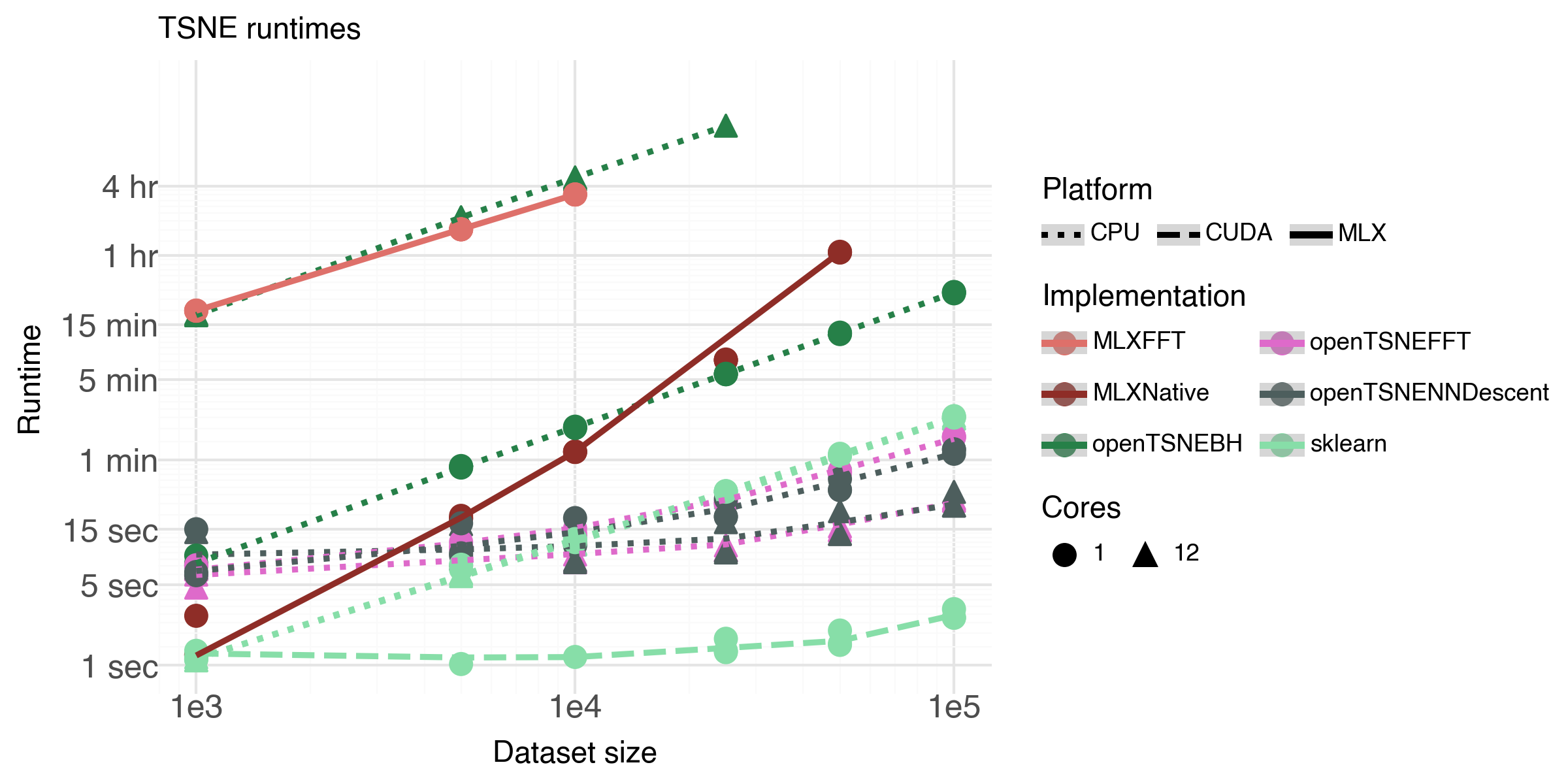
Seeing the speed for the MLXNative implementation for small test sets was exciting and promising. Increasing the data set sizes indicated poor scaling.
Moving on to the MLXFFT implementation, the runtimes were very disappointing. I believe this is mostly due to lacking necessary low level functionality in the FFT library in MLX.
Both the MLXNative and MLXFFT had ~90% GPU utilization when running the benchmarks, so it does seem compute streams were correctly routed.
The only other implementation with as poor performance as MLXFFT was the openTSNE implementation of BH-TSNE when using 12 cores. The single core version actually performs a lot better.
So in the end, unfortunately, simply moving computation to the GPU cores of the M4 Pro doesn’t immediately provide automatic performance gains.
Both openTSNEFFT and opentTSNENNDescent with 12 cores are pretty usable (but still 3x slower than cuML-accelerated TSNE).
In practice, when I have datasets with 200k+ points I want to explore, I will probably use some cloud computing (or subsample to ~100k).
On a positive note, using Claude Code to create these implementations (including debugging, refactoring, benchmarking, optimization) was quite straightforward.
The MLX implementations of TSNE, along with benchmarking scripts, are available on this branch on Github: https://github.com/vals/openTSNE/tree/mlx-acceleration. A notebook for producing the results figure is available at https://github.com/vals/Blog/tree/master/250331-mlx-tsne.
From around the web
“The Third University of Cambridge”: BBN and the Development of the ARPAnet
Wax Tailor - Que Sera (Phonovisions Symphonic Orchestra) [YouTube]
