
Serverless GPUs for fast TSNE visualization

TSNE visualization is useful to explore data but is time consuming without access to an Nvidia GPU. By using a serverless application at a cloud GPU provider you can seamlessly speed up TSNE visualization by four times compared to a fast locally running implementation.
To get intuition about latent representations and embeddings when modeling data, it is often useful to produce 2-dimensional visualizations using TSNE. These can be used to explore what aspects of data the models are learning.
Creating TSNE visualizations was initially very time consuming and only worked for small datasets. Over time, data structures, algorithmic innovations, and, approximations has increased the scale of data you can investigate with TSNE in shorter time.
Recently, RapidsAI made an extremely fast TSNE implementation on Nvidia GPUs. If you have access to a consumer level Nvidia GPU, hundreds of thousands of data points can be visualized in a few seconds.
If you do not have access to an Nvidia GPU, you can instead use openTSNE, a package with several highly optimized implementations of TSNE. These implementations are quite fast, but still an order of magnitude slower than the RapidsAI TSNE.
This makes it attractive to rent a GPU instance on a cloud vendor for interactive work. When exploring models and data, being able to quickly iterate between options and visualize results is very valuable. However, moving your work to a cloud instance means a lot of overhead. You also need to pay for running the GPU instance even though the GPU itself is only being used in occasional bursts.
Serverless deployment of GPU accelerated TSNE
As an alternative to renting a GPU instance, we can use a ‘serverless’ GPU provider just for the TSNE visualization that leverages a GPU.
The GPU provider Modal lets you define small applications consisting of single functions that can be executed using their API. When you call the function, a GPU instance starts up in a few seconds, runs the function on the input, sends back the result to the client, then shuts down the instance after a few minutes of activity. In this model you only pay for the few seconds that the function takes to run.
I created a small Modal service which performs TSNE using a serverless GPU with a local Python client library: https://github.com/vals/gpu-embedding-service. With this, running RapidsAI’s TSNE is just a matter of doing
from gpu_embedding import gpu_tsne
coords = gpu_tsne(X)No local GPU necessary. The data in X is sent to the service, which starts up in ten seconds if it’s not started, runs TSNE, then sends back the result as an array to the local client.
Serverless TSNE give results four times faster than local
Even with the overhead of needing to start the service and transfer the data it is about four times faster than running the equivalent TSNE locally on my Mac using 12 cores on 10-dimensional input embeddings.
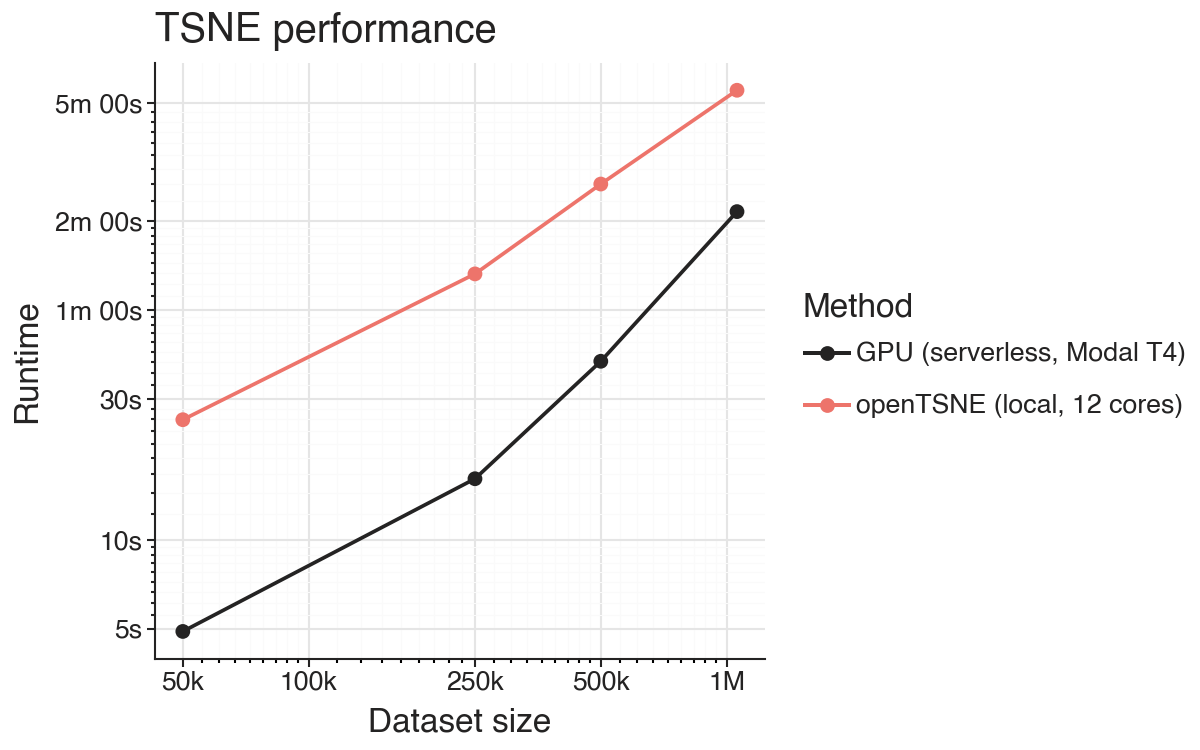
As input data grows larger (either in number of observations or dimensionality), the data transfer overhead will increase too, leading to diminishing returns. For many high-dimensional embeddings, this strategy won’t necessarily be useful compared to running openTSNE locally. However, in many cases the overhead is worth it.
For this benchmark I used 10-dimensional SCVI embeddings of the Asian Immune Diversity Atlas with variational batch encodings.
Do you ever need to run TSNE on a million observations? Not really. With a random sample of ~100,000 observations from the data you probably have enough points to notice outlier populations even when faceting to ~10 categories. More data points allow you to facet the data more, but there is also a point when it is hard to read and interpret too many facets.
Scripts for benchmarking and plotting are available on GitHub at https://github.com/vals/Blog/tree/master/260120-serverless-tsne
From around the web
